

CodeClash
Benchmarking Goal-Oriented Software Engineering
CodeClash
Benchmarking Goal-Oriented Software Engineering
Leaderboard
| Rank | Model | ELO |
|---|---|---|
| 1 |
 Claude Sonnet 4.5
Claude Sonnet 4.5
|
1385 ± 18 |
| 2 |
 GPT-5
GPT-5
|
1366 ± 17 |
| 3 |
o3
|
1343 ± 17 |
| 4 |
Claude Sonnet 4
|
1224 ± 17 |
| 5 |
GPT-5 Mini
|
1199 ± 16 |
| 6 |
 Gemini 2.5 Pro
Gemini 2.5 Pro
|
1124 ± 16 |
| 7 |
 Grok Code Fast
Grok Code Fast
|
1006 ± 19 |
| 8 |
 Qwen3 Coder
Qwen3 Coder
|
952 ± 20 |
Features
 Goals, not tasks
Goals, not tasks
No explicit GitHub issues or tasks. Given just a high-level objective, models decide for themselves what to build.
 Progress, not perfection
Progress, not perfection
Models evolve their codebases across multiple rounds, analyze gigabytes of logs, adapt strategies, implement algorithms, and make all high- to low-level decisions.
 Competition, not unit tests
Competition, not unit tests
Models compete via their codebases in arenas where success is measured by relative scores like income, territory control, survival.
Why CodeClash?
LMs have gotten pretty good at solving GitHub issues.

But real software development isn't a series of isolated tasks.
It's driven by goals.
Improve user retention, increase revenue, reduce costs. We build to achieve outcomes, not to close tickets.
What if AI evaluations reflected this dynamism of real-world software development?
We introduce CodeClash, an initial effort towards benchmarking goal-oriented software engineering
What is CodeClash?
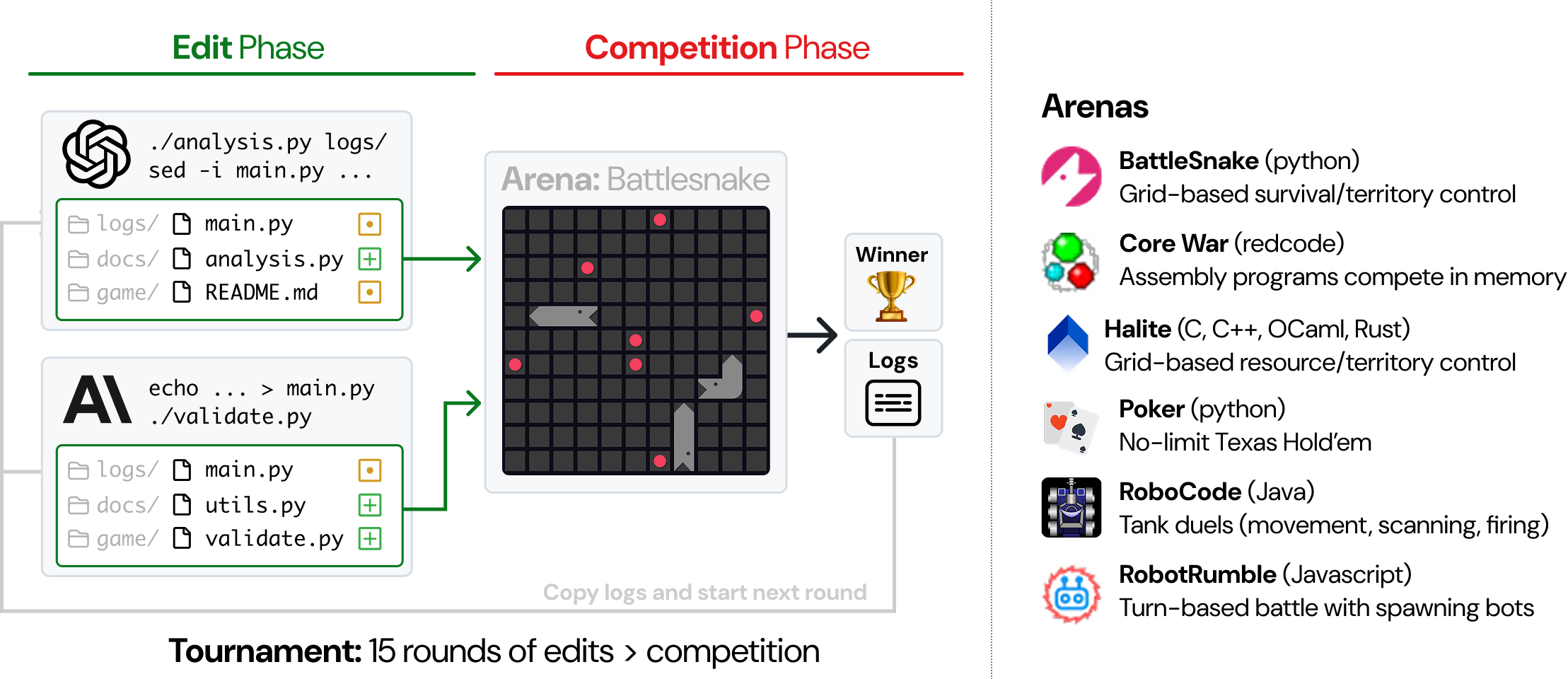
In CodeClash, models build and evolve their own codebase over multiple rounds.
Each round has two phases: edit, then compete.
In the edit phase, models get to improve their codebase as they see fit. Write notes, analyze past rounds, run test suites, refactor code -- whatever helps.
Then, they compete. Models' codebases face off in an arena.
Competition logs are then copied back to each model's codebase and the next round begins.The model that wins the most rounds is declared winner.
Our Results
We evaluate 8 models on 6 arenas across 1680 tournaments at 15 rounds each (25,200 rounds total), generating 50k agent trajectories in the process.
Our analysis reveals many directions for improvement.
 Far from Humans
Far from Humans
On RobotRumble, human solutions still beat the best LM by miles. Read more.
 Unable to Iterate
Unable to Iterate
Models struggle to improve over rounds, exhibiting a variety of failure modes.
 Decaying codebases
Decaying codebases
Model codebases accumulate tech debt and become messy rapidly. See examples.
CodeClash is fully open-source. Happy Clashing!
If you use CodeClash in your work, please cite our paper!
@misc{yang2025codeclashbenchmarkinggoalorientedsoftware,
title={CodeClash: Benchmarking Goal-Oriented Software Engineering},
author={John Yang and Kilian Lieret and Joyce Yang and Carlos E. Jimenez and Ofir Press and Ludwig Schmidt and Diyi Yang},
year={2025},
eprint={2511.00839},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2511.00839},
}